003_Position-Embedding
1. 为什么引入位置编码
现在的大模型架构基本都是基于Tansformer的Decoder架构的,之前讲Tansformer并没有提出一个问题,就是:输入序列内各元素之间的位置关系是无法捕捉到的,为什么呢?
其实,在RNN(递归神经网络)和CNN(Conv卷积神经网络)中,对于输入的位置关系是有所捕获的,想想RNN,不就是一个元素一个元素的预测,那他本身就带有了一定的位置关系(好吧,我当时也没想到有这层概念。或许,我应当再仔细分析分析,可能理解有误),在Tansformer论文里也提出了这一点:

那为啥Transformer本身不具有位置编码信息呢?整体上就是Attention并不会获取到输入序列(token与token之间)的位置信息,只有俩俩的相关性。
想想Attention机制就清晰了,假设只有一个长度为4的序列(batch_szie=1,seq_len=4),词嵌入维度大小为10,在草稿纸上画一画就可以知道,进行的操作只是一个点积操作,基本的意义就是对元素与元素之间的相似度计算结果(这是笔者自己尝试和思考之后的理解,不一定对),而在后续的整个Attention操作当中,都没有进行位置关系的操作,所以对序列的元素顺序进行打乱,依然可以得到对应相同的结果(我说的是相对),所以,为了解决这一问题,原论文作者就引入了位置编码向量了,好了,接下来我们看看有哪些位置编码以及引入方式(后续对位置编码用PE表示)。
思考:
位置编码向量应该长啥样?如何引入?
"The positional encodings have the same dimension as the embeddings, so that the two can be summed."
引入位置编码信息和不引入会有什么区别和影响?
简单理解就是使模型能区分
"从 我家 出门 到 你家"和"从 你家 出门 到 我家"如果是你,你会采取哪种方式进行位置信息的嵌入?
2. 基本的类型
2.1 三角函数式的PE
中英文对照论文:Attention Is All You Need
这是一种绝对位置编码方式
直接对word embedding和position embedding相加送入到模型
是Transformer架构最初的编码方式
首先,论文里面说 "The positional encodings have the same dimension as the embeddings, so that the two can be summed.",那位置编码向量也就跟embedding之后的大小是一致的,然后将PE矩阵和Embedding后的矩阵直接相加得到结果,这就是作者的引入方式。我们所有最初的测试都按照batch_size=1的数据进行分析,也就是现在只考虑一个样本序列,假设他的shape为[seq_len, embedding_dim],OK,我们继续详读论文。

就上面公式,其中:
表示第个token, 和 表示token对应的embedding(第奇数个和偶数个分别采用cos和sin)
ransformer的作者表示:
他们还尝试使用学习的位置嵌入 ,发现这两个版本产生了几乎相同的结果。他们选择正弦版本,因为它可能允许模型预测到时候处理比训练期间遇到的序列长度更长的句子。
思考:
公式中对于2i+1个分量的分母指数那块为啥是2i?
那哪里体现了位置信息呢?
想想公式,pos
公式到底是怎样来的呢?是怎样的原理哇?
在Attention之前进行了qkv矩阵映射,那位置编码是对哪些做哪些不做?
只对q和k做位置编码,对value不做,因为value是token本身的特征信息
2.2 可学习的PE
很显然,绝对位置编码的一个最朴素方案是不特意去设计什么,而是直接将位置编码当作可训练参数,比如最大长度为512,编码维度为768,那么就初始化一个512×768的矩阵作为位置向量,让它随着训练过程更新。现在的BERT、GPT3等模型所用的就是这种位置编码(后续会专门整理Bert这块的内容)。
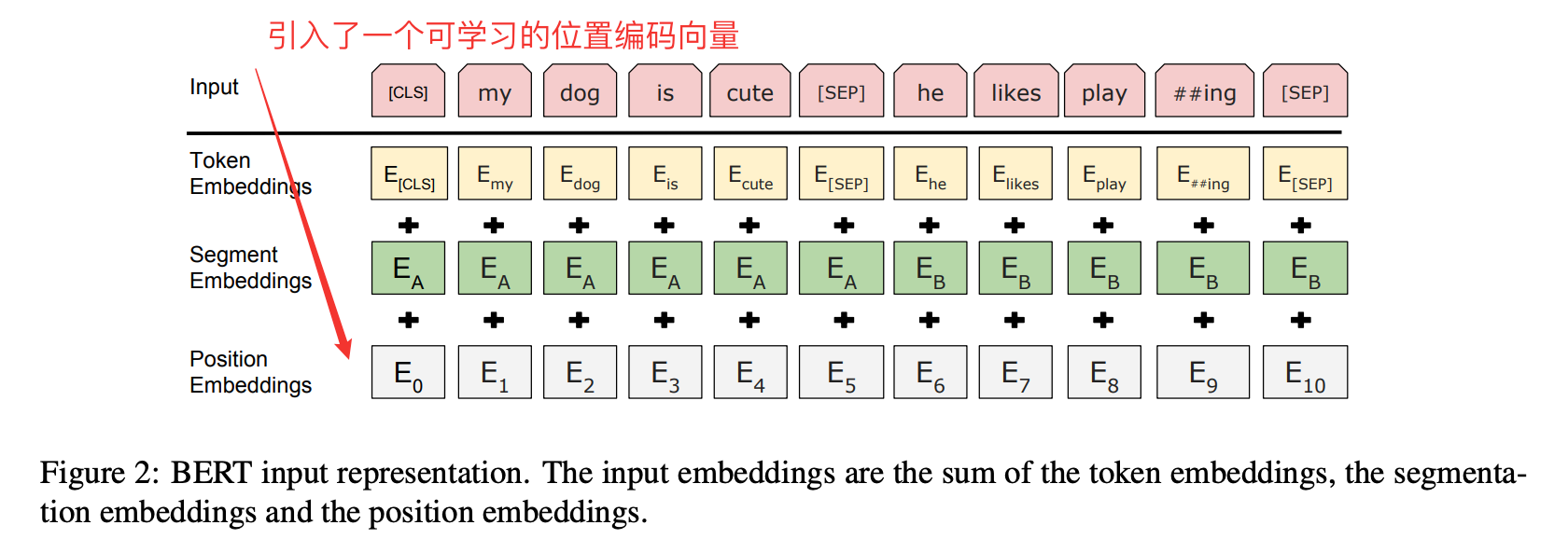
对于这种训练式的绝对位置编码,一般的认为它的缺点是没有外推性(推理阶段确保模型能处理远超预训练时的文本长度),即如果预训练最大长度为512的话,那么最多就只能处理长度为512的句子,再长就处理不了了。当然,也可以将超过512的位置向量随机初始化,然后继续微调。
2.3 RoPE(旋转位置编码)
\left\langle f_{q}\left(\boldsymbol{x}_{m}, m\right), f_{k}\left(\boldsymbol{x}_{n}, n\right)\right\rangle=g\left(\boldsymbol{x}_{m}, \boldsymbol{x}_{n}, m-n\right)使用绝对位置编码的方式实现相对位置信息编码
"Specifically, the proposed RoPE encodes the absolute position with a rotation matrix and meanwhile incorporates the explicit relative position dependency in self-attention formulation"
大模型主流位置编码方式
现在的LLama系列、GPT4系列、DeepSeek系列、Qwen系列等都用的是这种方式。(代码实现可能有所变化)
为什么要找到这样一个函数呢?(摘抄自参考博客)
因为我们希望 fq 和 fk 进行内积操作,受到他们相对位置的影响。(符合自然语言的习惯)
1.两个词相对位置近的时候(m-n小),内积可以大一点。
2.两个词相对位置远的时候(m-n大),内积可以小一点。(长度衰减)
直观理解
2.4 ALiBi
3. 代码实现
3.1 三角位置编码
embedding_dim = 1024
seq_len = 32
x = torch.randn(seq_len, embedding_dim)
pe = torch.ones_like(x)
for seq_idx in range(seq_len):
pos = seq_idx
for emb_idx in range(embedding_dim):
tmp = pos / (10000 ** (emb_idx / embedding_dim)) # 这里跟论文的2i有点不一样
if emb_idx & 0 == 0:
pe[seq_idx][emb_idx] = torch.sin(torch.tensor(tmp))
else:
pe[seq_idx][emb_idx] = torch.cos(torch.tensor(tmp))
plt.imshow(pe.numpy().T, cmap='hot', aspect='auto')
plt.xlabel('Position')
plt.ylabel('Embedding Dim')
plt.colorbar()
plt.show()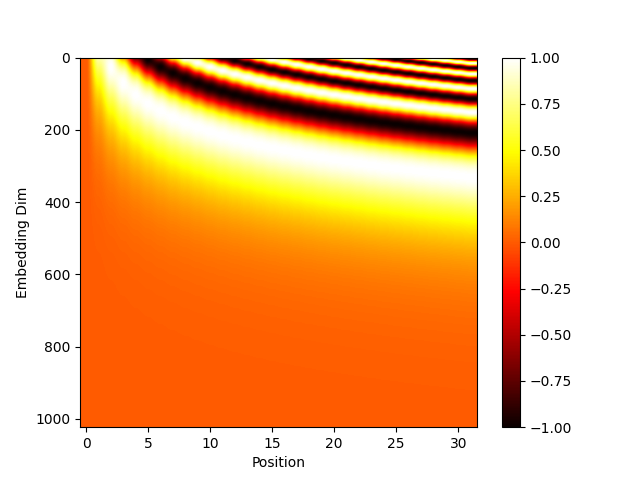
4. 长文本外推技术
随机位置法、线性插值法
4.1 位置内插(PI)
4.2 NTK-Aware
5. 模型上下文能力
通过位置编码,我们可以进一步优化如下效果
- 位置信息
- 注意力稀释问题
参考资料
中英文对照论文:Attention Is All You Need