001_Transformer
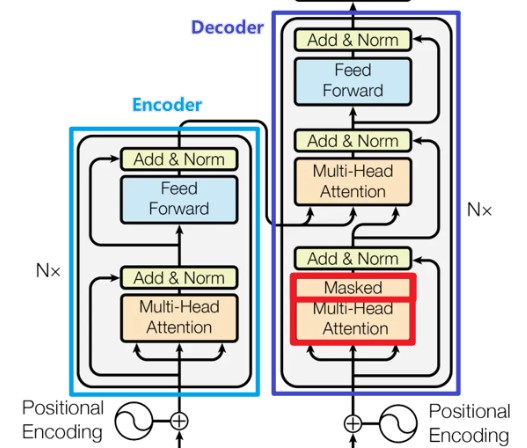
1. 基本架构
中英文对照论文:Attention Is All You Need

1.1 编码器
编码器由N = 6 个完全相同的层堆叠而成。 每一层都有两个子层。 第一个子层是一个multi-head self-attention机制,第二个子层是一个简单的、位置完全连接的前馈网络(FFN)。 我们对每个子层再采用一个残差连接(代码使用short_cut或者res_net指代),接着进行层标准化(代码用Norm指代)。也就是说,每个子层的输出是,其中 是由子层本身实现的函数。 为了方便这些残差连接,模型中的所有子层以及嵌入层产生的输出维度都为 = 512。
1.2 解码器
解码器同样由N = 6 个完全相同的层堆叠而成。除了每个编码器层中的两个子层之外,解码器还插入第三个子层,该层对编码器堆栈的输出执行multi-head attention。 与编码器类似,我们在每个子层再采用残差连接,然后进行层标准化。 我们还修改解码器堆栈中的self-attention子层,以防止位置关注到后面的位置。 这种掩码结合将输出嵌入偏移一个位置,确保对位置的预测 i 只能依赖小于i 的已知输出。——Masking(sequence masking)
1.3 Pipeline
Encoder:
Decoder:
根据架构图同上整理
2. 主要组件
残差连接(short cut)
注意力机制(self attention)
Scaled Dot-Product Attention
Multi-Head Attention
Cross Multi-Head Attention
全连接层(FFN)
归一化层(Norm)
Dropout
掩码机制(Masking)
位置编码(Position Embedding)
2.1 Scaled Dot-Product Attention
就是标准的注意力机制,需要除以
Attention可以描述为将query和一组 key-value对 映射到输出(output),其中query、key、value和 output都是向量(vector)。 输出为value的加权和,其中分配给每个value的权重通过query与相应key的兼容函数来计算。
 $$ Attention(Q, K, V)=softmax(\frac{Q K^{T}}{\sqrt{d_{k}}}) V $$
$$ Attention(Q, K, V)=softmax(\frac{Q K^{T}}{\sqrt{d_{k}}}) V $$ 2.2 Multi-Head self Attention
 $$ MultiHead(Q, K, V) = Concat(head_{1}, \ldots, head_{h}) W^{O} $$
$$ MultiHead(Q, K, V) = Concat(head_{1}, \ldots, head_{h}) W^{O} $$ 其中:
2.3 Cross Multi-Head Attention
将encoder的key和value与decoder的query进行attention,论文好像没有明确指出这一块内容

2.4 FFN
Position-wise 类型的 Feed-Forward Networks

论文指出了几点,我这里height light了一下:
- 每个编码和解码层都有一个扩展的FFN子层
- 两个线性转换和一个默认的ReLU激活函数
- 说相当于用了个两个大小为1的卷积核?
- FFN层先是将输入(MHA的输出)进行进行✖️4的操作,然后再转成(两个线性转换)。
3. 其他组件
3.1 掩码机制(Masking)
mask 表示掩码,它对某些值进行掩盖,使其在参数更新时不产生效果。Transformer 模型里面涉及两种 mask,分别是 padding mask 和 sequence mask。
两个的计算原理一样:xxxx(待补充)
思考:为什么需要添加这两种mask码呢???
padding mask
什么是 padding mask 呢?因为每个批次输入序列长度是不一样的也就是说,我们要对输入序列进行对齐。具体来说,就是给在较短的序列后面填充 0。但是如果输入的序列太长,则是截取左边的内容,把多余的直接舍弃。因为这些填充的位置,其实是没什么意义的,所以我们的attention机制不应该把注意力放在这些位置上,所以我们需要进行一些处理。
具体的做法是,把这些位置的值加上一个非常大的负数(负无穷),这样的话,经过 softmax,这些位置的概率就会接近0!
思考:上句中的 "这些位置" 指哪些位置呢?
- pytorch 代码实现
def attention(query, key, value, mask=None, dropout=None):
"Compute 'Scaled Dot Product Attention'"
d_k = query.size(-1)
scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(d_k)
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9) # mask步骤,用 -1e9 代表负无穷
p_attn = F.softmax(scores, dim = -1)
if dropout is not None:
p_attn = dropout(p_attn)
return torch.matmul(p_attn, value), p_attnsequence mask
sequence mask 是为了使得 decoder 不能看见未来的信息。对于一个序列,在 time_step 为 t 的时刻,我们的解码输出应该只能依赖于 t 时刻之前的输出,而不能依赖 t 之后的输出。因此我们需要想一个办法,把 t 之后的信息给隐藏起来。这在训练的时候有效,因为训练的时候每次我们是将target数据完整输入进decoder中地,预测时不需要,预测的时候我们只能得到前一时刻预测出的输出。
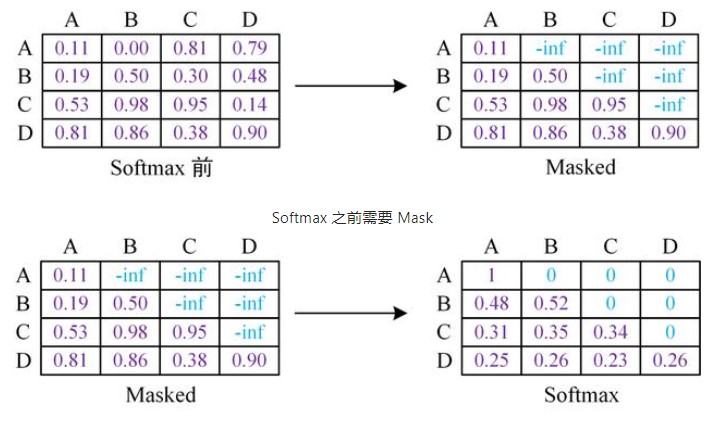
那么具体怎么做呢?也很简单:产生一个上三角矩阵,上三角的值全为0。把这个矩阵作用在每一个序列上,就可以达到我们的目的。
思考:
- decoder 中需要 padding mask 吗?
3.2 位置编码(Position Embedding)

论文指出使用的是三角位置编码,可以想想,为啥可以实现位置编码呢?有怎样的效果呢?(后续位置编码章节会讲)
3.3 Other
由于别的一些组件适合一个章节讲解,有很多细节知识,单独列成模块讲解了
包括:
别的Attention
位置编码
Norm
Activation
等等
4. 补充
MQA
GQA
Flash Attention
重计算
KV-cache
Page Attention
5. 代码实现
n. 面试问题
为什么需要qkv参数矩阵,不能共用同一个吗?
每个的作用不一样,………………
为啥要除以
代码演示矩阵乘法使用缩放和不使用缩放的对比。
当 的值比较小的时候,两种点积机制(additive 和 Dot-Product)的性能相差相近,当 比较大时,additive attention 比不带scale 的点积attention性能好。 我们怀疑,对于很大的 值,点积大幅度增长,将softmax函数推向具有极小梯度的区域。 为了抵消这种影响,我们缩小点积 倍。
为什么拆多头?有什么作用?
子空间信息多样化(有点类似卷积的多个
channel)。好像还可以减少计算量(显存占用量/计算量好像减少了倍)self Attention如何实现多模态?
交叉注意力实现。
self attention和传统的attention的区别?
想想Transformer架构中存在哪些问题?