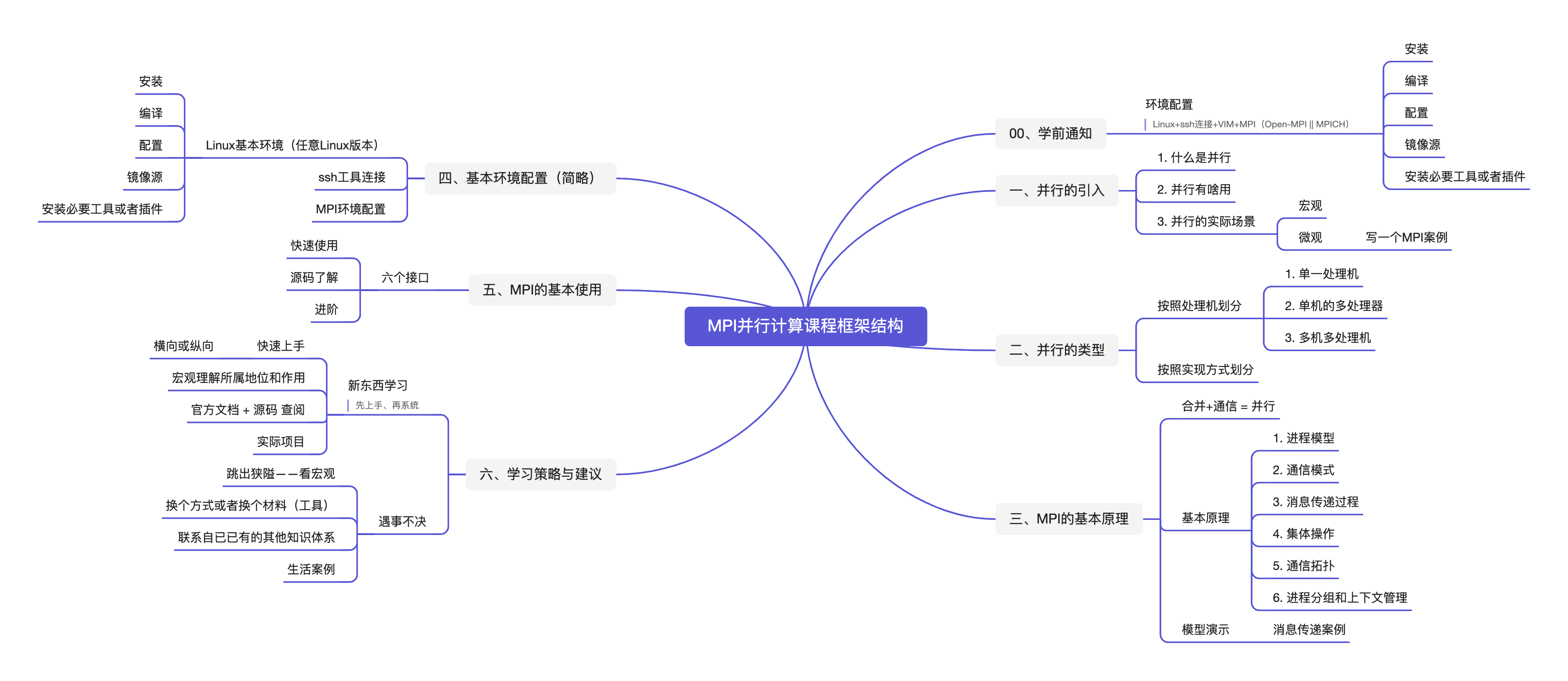
MPI并行计算
学前须知!
学习前要自己配置一个Linux虚拟机,并尝试使用远程连接工具连接访问。 自己提前查阅相关环境安装资料进行环境配置(不懂就问AI或者浏览器),基本环境要求如下:
Linux + ssh连接 + VIM + MPI (Open-MPI 或者 MPICH)
一、并行的引入
你要用python爬取三个网页的数据,你会一个一个爬吗?
1.1 基本概念
进程:程序运行的实例,一个程序运行起来就相当于一个进程。
线程:线程是进程中的更小执行单元,一个进程可以包含多个线程,共享进程资源。不同的线程可以并行执行,处理同一任务的不同部分。
节点:可以看做一台服务器或者PC机。
消息:消息是数据和控制信息的封装,可以包含需要传递的任何信息,如数字、字符、结构体或对象。
消息传递:创建消息 ——> 发送消息 ——> 接收消息 ——> 处理消息(或响应)
创建消息:在一个进程或节点中创建待发送的信息。 发送消息:将消息发送给另一个进程或节点。 接收消息:接受来自其他进程或节点的消息。 处理消息:接收端处理收到的消息,执行相应操作。
这里主要讲解MPI实现分布式消息传递
分布式系统:是一组电脑(服务器),透过网络相互连接传递消息 与通信后并协调它们的行为而形成的系统。
1.2 什么是并行?
并行计算(英语:parallel computing)一般是指许多指令得以同时进行的计算模式。在同时进行的前提下,可以将计算的过程分解成小部分,之后以并发方式来加以解决[1]。
它广泛应用于科学计算、数据分析、大规模仿真等领域。随着多核处理器和分布式计算系统的发展,并行计算变得愈发重要。
1.3 并行有啥用?
我觉得主要就是:提高资源利用率、提升计算性能
不管是单核单处理器、多处理机、还是分布式,都是尽最大可能让进程去占用资源,不让空闲。
1.4 并行的实际案例
并行计算可以在不同的硬件架构上实现,包括单核单处理器、多处理器系统和分布式系统。
这里就拿单核单处理器简单演示
在单核单处理器的环境下,虽然硬件不支持真正的并行计算,但可以通过多线程或协程实现并行化。典型案例包括:
多线程编程:
案例:在 Python 中使用
threading模块实现并发任务,例如网页抓取。示例代码:
pythonimport threading import requests # 用于存储结果的字典 results = {} # 爬取URL的函数 def fetch_url(url): try: response = requests.get(url) # 将状态码和内容存储到结果字典中 results[url] = { 'status_code': response.status_code, 'text': response.text # 存储完整的爬取内容 } # 打印状态信息 print(f'Fetched {url} with status {response.status_code}') except requests.exceptions.RequestException as e: # 处理请求异常 results[url] = { 'status_code': None, 'error': str(e) } print(f'Error fetching {url}: {str(e)}') # 要爬取的URL列表 urls = [ 'https://www.baidu.com?wd=小狗', 'https://www.coderethan.fun/生活与算法/', 'https://zh.wikipedia.org/wiki/分布式计算' ] # 存储线程的列表 threads = [] # 创建和启动线程 for url in urls: thread = threading.Thread(target=fetch_url, args=(url,)) threads.append(thread) thread.start() # 等待所有线程完成 for thread in threads: thread.join() # 输出整理后的结果 for url, data in results.items(): print(f"\nURL: {url}") print(f"Status Code: {data['status_code']}") if 'error' in data: print(f"Error: {data['error']}") else: print(f"Content length: {len(data['text'])} characters") # 输出内容长度
后面我们会讲分布式环境下的并行计算,MPI实现
二、并行的类型
2.1 按照处理机划分
单一处理机、单机的多处理器、多机多处理机 MPI 的共内存和非共内存的通信模式不同,一个基于总线、一个基于network
- 共享内存模型:所有处理器共享相同的内存空间,任务间通过共享内存交换数据。这种模式简单高效,但扩展性有限。(该模型是IPC进程间通信,多个进程同时访问同一块内存区域,具体实现有多种,比如:信号量机制)
- 分布式内存模型:每个处理器有独立的内存,任务间通过网络通信(如消息传递接口MPI)交换数据。适合大规模分布式系统,扩展性强。
- 混合模型:结合共享内存和分布式内存模型,适合大型集群内的多核节点,比如MPI与OpenMP的结合使用。
2.2 按照实现方式划分
MPI(消息传递接口):用于分布式并行计算,适合需要在不同节点之间进行通信的任务。(只是一个规范,具体实现有不同的厂商或者社区实现)
MPI的实现
MPI是一个标准化的接口,有多种实现,适用于不同的计算需求和环境。主要的MPI实现有:
MPICH:
特点:一个广泛使用的开源MPI实现,遵循MPI标准,强调可移植性和性能。
用途:研究、教育和生产环境中的高性能计算。
Open MPI:
特点:另一个流行的开源MPI实现,支持多种网络协议和多种平台,具有灵活的架构。
用途:科学计算、工程模拟、大规模并行计算。
Intel MPI:
特点:由Intel提供,优化用于Intel架构,支持高性能计算。
用途:特别适用于需要高性能的计算应用,如天气预测、流体动力学等。
MVAPICH:
特点:为高性能计算和InfiniBand网络优化的MPI实现。
用途:适用于需要大规模并行计算的科学和工程应用。
Microsoft MPI (MS-MPI):
特点:在Windows平台上实现的MPI,兼容MPI标准,适用于Windows HPC Server。
用途:在Windows环境中进行高性能计算。
LAM/MPI:
特点:一个较早的MPI实现,现已合并到Open MPI中,主要用于教学和研究。
用途:用于学习和小规模并行计算。OpenMP:适用于多核处理器的并行计算,使用共享内存模型,简单易用。
CUDA:NVIDIA公司提供的GPU并行计算框架,用于GPU加速的并行计算。
Hadoop/Spark:大数据处理框架,支持分布式数据处理和MapReduce并行计算模式。
三、MPI的基本原理
合并+通信 = 并行
3.1 基本原理
1. MPI的架构
MPI使用分布式内存模型,这意味着每个进程都有自己的独立内存空间。进程之间的通信通过消息传递实现,不共享内存,因此避免了共享内存架构中的竞争条件和数据一致性问题。MPI适用于需要跨多个节点运行的任务,因此广泛用于大规模并行计算场景。
2. 进程和通信
MPI程序通常启动多个进程,每个进程执行相同的代码,但可以基于其独特的ID执行不同的任务。进程的ID(通常称为rank)是进程的唯一标识,MPI使用这个ID来标识进程并确定数据传输的目标。
- 通信模型:MPI使用消息传递(Message Passing)模型,包括点对点通信(单个进程与另一个进程通信)和集体通信(多个进程参与的通信)。
- 点对点通信:常用的函数包括
MPI_Send和MPI_Recv,分别用于发送和接收消息。每条消息包含源进程ID、目标进程ID、消息数据、数据类型和标签等信息。 - 集体通信:MPI提供多种集体通信模式,如广播(
MPI_Bcast)、聚合(MPI_Reduce)、散播(MPI_Scatter)、收集(MPI_Gather)等,用于多个进程之间的数据传输和聚合。
3. MPI的通信模式
MPI支持两种基本的通信模式:
- 同步通信:在同步通信中,发送方会等待接收方收到消息后,才能继续执行。这种方式适用于需要确保消息到达的情景,但会导致一定的同步开销。
- 异步通信:异步通信允许发送方在消息尚未接收完毕时继续执行。常用的异步通信函数如
MPI_Isend和MPI_Irecv(其中"I"表示"Immediate"),能提升程序并发性,但需要更细致的同步控制。
4. MPI的基本函数
MPI标准中包含了一系列函数,以下是一些最常用的函数:
初始化和终止
:
MPI_Init:初始化MPI环境,必须在所有MPI函数之前调用。MPI_Finalize:终止MPI环境,所有MPI函数之后必须调用。
通信
:
MPI_Send:同步发送消息,用于点对点通信。MPI_Recv:同步接收消息,通常和MPI_Send配合使用。MPI_Isend和MPI_Irecv:异步发送和接收消息。MPI_Bcast:广播,将一条消息发送给所有进程。MPI_Scatter:数据散播,将不同的数据片段分发给各个进程。MPI_Gather:数据收集,将各进程的数据收集到一个进程中。MPI_Reduce:聚合,将各进程的数据聚合为一个单一结果。
环境查询
:
MPI_Comm_size:获取总的进程数。MPI_Comm_rank:获取当前进程的ID(rank)。
5. MPI的数据类型和消息标签
MPI传递消息时需要明确数据类型和标签:
- 数据类型:MPI支持多种基础数据类型(如
MPI_INT、MPI_FLOAT等)和自定义数据类型。MPI还允许用户定义结构化数据类型,通过MPI_Type_create_struct等函数创建适合具体应用的数据类型。 - 消息标签:每条消息附带一个标签,用于区分不同类型的消息。标签在发送和接收时需一致,接收方可以通过标签区分不同的消息。
6. 通信域(Communicator)
通信域定义了进程组及其作用范围。MPI中的默认通信域是MPI_COMM_WORLD,表示所有进程组成的通信域。进程可以在不同的通信域内工作,这样便于实现多个子任务并行执行。
7. MPI中的常见通信模式
- 单主多从(Master-Worker)模式:一个主进程负责任务分发,其他工作进程(从进程)执行计算任务,并将结果返回给主进程。这种模式适合有集中管理需求的任务分解。
- 数据并行模式:每个进程处理数据的一部分,适合矩阵乘法、图像处理等需要对大规模数据进行并行处理的场景。
- 流水线(Pipeline)模式:各个进程依次执行不同的步骤,适合流水线任务,如图像处理的多步操作等。
8. MPI的优势和劣势
- 优势:
- 高扩展性,适用于大规模计算。
- 能有效利用分布式集群的计算能力。
- 允许精确控制进程间的数据传输,减少冗余通信。
- 劣势:
- 编程复杂度较高,尤其在处理非同步通信时。
- 需要显式管理通信和数据分布。
- 不适用于共享内存架构。
3.2 模型演示
发微信
四、基本环境配置(简略)
4.1 Linux环境
建议安装无GUI的系统
Mac OS通过Parallels Desktop安装Linux镜像
4.2 ssh工具
- xshell
- OpenSSH
- PuTTY
- Termius
- VSCode + Remote - SSH扩展
ssh user@host_ip4.3 VIM编辑器
安装
# Ubuntu版本
sudo apt update
sudo apt install vim# Centos7及以下
sudo yum install vim# Centos8及以上
sudo dnf install vim# Ubuntu版本
sudo apt update
sudo apt install vim# 安装验证
vim --version使用
扫一遍,当手册使用,用哪查哪
4.4 MPI环境
OpenMPI
MPICH
4.4.1 安装
4.4.2 编译
4.4.3 配置
4.4.4 了解
对这块感兴趣的可以自己了解了解
安装完 Open MPI 或 MPICH 后会自动生成一套与 MPI 相关的工具(包括编译器和运行程序),是因为这些工具都是为开发和执行 MPI 程序而专门设计的,包含了消息传递接口的支持库。具体来说,它们提供了以下几种关键工具:
1. MPI 编译器包装器
mpicc、mpic++、mpif90等编译器工具并不是真正的编译器,而是包装器(wrapper)。它们的作用是 简化编译过程,通过调用系统的 C、C++ 或 Fortran 编译器(如 GCC、gfortran 等),并自动添加 MPI 库和头文件的路径和链接选项。
例如,
mpicc的实际效果等价于在编译命令中手动添加包含路径(-I)和链接选项(-L和-l),从而找到 MPI 库和头文件:bashmpicc my_mpi_program.c -o my_mpi_program实际上等价于:
bashgcc my_mpi_program.c -o my_mpi_program -I/path/to/mpi/include -L/path/to/mpi/lib -lmpi使用
mpicc等包装器工具后,用户不需要记住 MPI 的具体路径或链接细节,这大大简化了编译过程。
2. MPI 程序的运行工具
mpirun或mpiexec是用于运行 MPI 程序的工具。这些工具可以 在多个进程上运行同一个 MPI 程序,并管理各个进程之间的通信。
在多核环境或集群中,
mpirun会分配不同的计算节点或 CPU 核心给每个进程,并通过底层网络协议(如 TCP、Infiniband)完成进程间的数据传输。使用示例:
bashmpirun -np 4 ./my_mpi_program上面的命令将启动 4 个 MPI 进程,并在每个进程中运行
my_mpi_program,从而实现并行计算。
3. 为什么编译器和运行程序会自动生成?
- 安装时的配置:在安装 Open MPI 或 MPICH 时,安装程序会自动配置这些工具,以便与系统的编译器集成,并确保库文件路径和头文件路径正确设置。
- 标准化工具链:MPI 编译器和运行工具是 MPI 标准的一部分,通过安装 MPI 实现,自动生成这些标准化的工具,便于开发者编译和执行 MPI 程序。
五、MPI的基本使用
六个接口
nclude <stdio.h>
#include <mpi.h>
int main(int args, char *argv[])
{
int myid, size;
MPI_Init(&args, &argv);
MPI_Comm_rank(MPI_COMM_WORLD, &myid);
MPI_Comm_size(MPI_COMM_WORLD, &size);
int MPI_Recv(void *buf, int count, MPI_Datatype type, int source,
int tag, MPI_Comm comm, MPI_Status *status);
// 发送端和接收端采用同一个变量命名,原因是子任务内部是局部性的
// 其他参数同Send
// 不同:*status:返回状态(编程时忽略)
int MPI_Send(const void *buf, int count, MPI_Datatype type, int dest,
int tag, MPI_Comm comm);
// *buf: 缓冲区; count * type = 数据大小;
// dest: 目的进程编号; tag: 消息标志(消息通讯的匹配); comm: 当前的通讯域
printf("Hello World For MPI! I am Node %d of %d\n", myid, size);
MPI_Finalize();
return 0;
}5.1 快速使用
5.2 源码了解
5.3 进阶
5.3.1 分布式实现
步骤一:Linux安装配置MPICH
步骤二:MacOS安装配置OpenMPI
步骤三:配置 SSH
为了使 MPI 可以在 Linux 和 MacOS 之间无密码运行
- 在 Linux 上生成 SSH 密钥: 在 Linux 终端中输入:
实现复信
ssh-keygen -t rsa按照提示,按回车接受默认设置,密钥将生成在 ~/.ssh/id_rsa 和 ~/.ssh/id_rsa.pub。
将公钥复制到 MacOS 机器: 使用以下命令将公钥复制到 MacOS 机器:
ssh-copy-id user@mac-ip-address替换
user为 MacOS 用户名,mac-ip-address为 MacOS 机器的 IP 地址。测试 SSH 连接: 在 Linux 上测试 SSH 连接:
ssh user@mac-ip-address确保可以无密码登录。
步骤四:案例演示
Linux为主、mac为子
MPI 程序:计算从 1 到 N 的总和
#include <mpi.h>
#include <stdio.h>
#include <stdlib.h>
int main(int argc, char** argv) {
MPI_Init(&argc, &argv); // 初始化 MPI
int world_size, world_rank;
MPI_Comm_size(MPI_COMM_WORLD, &world_size); // 获取进程总数
MPI_Comm_rank(MPI_COMM_WORLD, &world_rank); // 获取当前进程的编号
// 定义 N 的值
int N = 100000; // 要计算的最大值
int local_sum = 0; // 当前进程计算的部分和
int total_sum = 0; // 总和
// 计算每个进程负责的范围
int portion_size = N / world_size; // 每个进程负责的部分大小
int start = world_rank * portion_size + 1; // 开始值
int end = (world_rank == world_size - 1) ? N : start + portion_size - 1; // 结束值
// 每个进程计算自己的部分和
for (int i = start; i <= end; i++) {
local_sum += i; // 计算从 start 到 end 的和
}
// 打印每个进程的计算状态
printf("Process %d on %s calculated local sum from %d to %d = %d\n", world_rank, getenv("HOSTNAME"), start, end, local_sum);
// 使用 MPI_Reduce 将每个进程的部分和加到总和中
MPI_Reduce(&local_sum, &total_sum, 1, MPI_INT, MPI_SUM, 0, MPI_COMM_WORLD);
// 主进程打印结果
if (world_rank == 0) {
printf("Total sum from 1 to %d = %d\n", N, total_sum);
}
MPI_Finalize(); // 结束 MPI
return 0;
}Linux
mpicc mpi_sum.c -o mpi_sum.out
mpirun -np 4 -host host1ip,host2ip ./mpi_sum.out
top六、学习策略与建议
6.1 新东西学习
先上手、再系统(先完成、再完善)
快速上手(横向或纵向)
宏观理解所属地位和作用
查阅——官方文档 + 源码 + ……
实际项目
6.2 遇事不决
跳出狭隘——看宏观
换个方式或者换个材料(工具)
联系自已已有的其他知识体系
生活案例
6.3 知识体系构建
这里我借用刘崇军老师给说说的话:
对于终生学习来说,集中注意力很重要,构建概念体系很重要。市面上重要的信息很多:投资理财、人际关系、情商、人性。。。对于终生学习来说这些简单了解即可,不要过度分散注意力。 我个人的路径:深入了解一个专业,找到专业中需要解决的问题。个人能力与解决问题之间的差距在哪里?怎么样去补齐这个差距?行业的自动化程度高么?从哪里开始进行自动化?行业未来的方向是什么?我能做什么准备?整个过程走下来,人生也就到中后期了。